
Do you want to block a certain directory or folder from being crawled by search engine bots and other web crawlers? If yes, just follow the following steps below.
What is a directory?
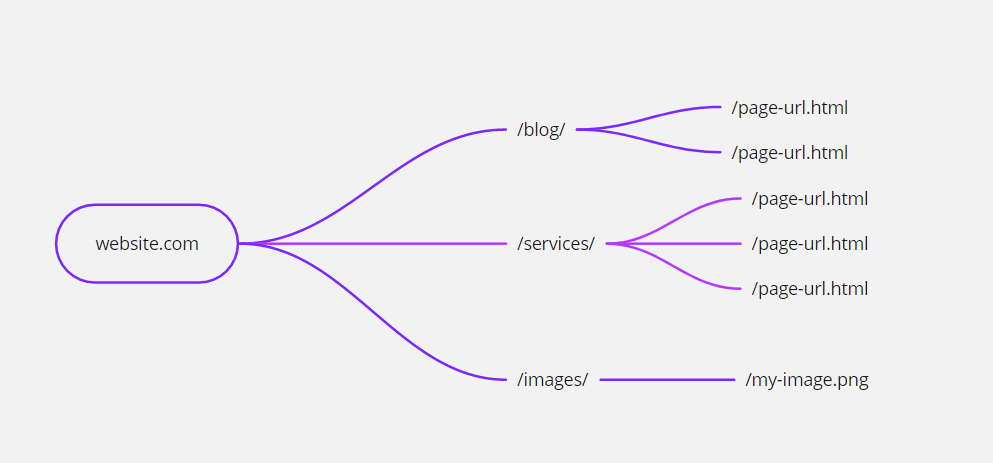
A directory is a sub-section of your website where you put certain information about your website. Usually, web developers use different directories to store information like /images/ for storing images, /blog/ for storing blog posts, /services/ for storing service-related pages, and so on.
Robots.txt to disallow a directory
User-agent: *
Disallow: /images/
Disallow: /services/Above robots.txt blocks /images/ and /services/ directories from being crawled. * stands for all the crawlers.
Level of directories
Root directory: Public_html is the root directory of your website and can have all kinds of content in it.
www.example.com/yourpage.html (This page is in root directory)Directory: Directories under public_html folder is called directories.
www.example.com/images/my-pic.png (This picture is in the /images/ directory)Sub-directories: Directories inside the directories are called sub-directories.
www.example.com/services/web/food-delivery-website.html (Here /web/ is a sub-directory)






